
最近公司业务急数发展,公司一张大表已经接近20亿数据,目前数据规格是阿里云的云数据库PolarDB 8核32G.考虑到后续还会持续增加,势必会影响MySQL的读写性能,所以需要对这张大表进行分表.
一、什么是ShardingSphere?
shardingsphere 是一款开源的分布式关系型数据库中间件,为 Apache 的顶级项目.其前身是 sharding-jdbc 和 sharding-proxy 的两个独立项目,后来在 2018 年合并成了一个项目,并正式更名为 ShardingSphere.
其中 sharding-jdbc 为整个生态中最为经典和成熟的框架,最早接触分库分表的人应该都知道它,是学习分库分表的最佳入门工具.
如今的 ShardingSphere 已经不再是单纯代指某个框架,而是一个完整的技术生态圈.由三款开源的分布式数据库中间件 sharding-jdbc、sharding-proxy 和 sharding-sidecar 所构成.前两者问世较早,功能较为成熟,是目前广泛应用的两个分布式数据库中间件.
二、为什么选择ShardingSphere?
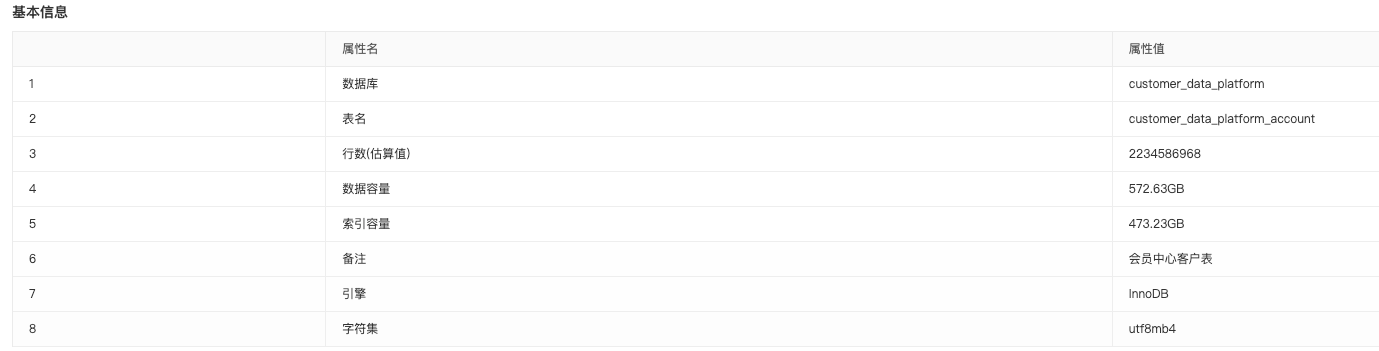
从目前市面上主流的分库分表工具包括ShardingSphere、Cobar、Mycat、TDDL、MySQL Fabric等,进行一个简单的对比
Cobar:
Cobar是阿里巴巴开源的一款基于MySQL的分布式数据库中间件,提供了分库分表、读写分离和事务管理等功能。它采用轮询算法和哈希算法来进行数据分片,支持分布式分表,但是不支持单库分多表。
它以 Proxy 方式提供服务,在阿里内部被广泛使用已开源,配置比较容易,无需依赖其他东西,只需要有Java环境即可。兼容市面上几乎所有的 ORM 框架,仅支持 MySQL 数据库,且事务支持方面比较麻烦。
Mycat:
Mycat是社区爱好者在爱里Cobar基础上进行二次开发的,也是一款比较经典的分库分表工具。它以 Proxy 方式提供服务,支持分库分表、读写分离、SQL路由、数据分片等功能。
兼容市面上几乎所有的 ORM 框架,包括 Hibernate、MyBatis和 JPA等都兼容,不过,美中不足的是它仅支持 MySQL数据库,目前社区的活跃度相对较低。
TDDL:
TDDL是阿里巴巴集团开源的一款分库分表解决方案,可以自动将SQL路由到相应的库表上。它采用了垂直切分和水平切分两种方式来进行分表分库,并且支持多数据源和读写分离功能。
TDDL 是基于 Java 开发的,支持 MySQL、Oracle 和 SQL Server 数据库,并且可以与市面上 Hibernate、MyBatis等 ORM 框架集成。
不过,TDDL仅支持一些阿里巴巴内部的工具和框架的集成,对于外部公司来说可能相对有些局限性。同时,其文档和社区活跃度相对较低。
MySQL Fabric:
MySQL Fabric是MySQL官方提供的一款分库分表解决方案,同时也支持 MySQL其他功能,如高可用、负载均衡等。它采用了管理节点和代理节点的架构,其中管理节点负责实时管理分片信息,代理节点则负责接收并处理客户端的读写请求。
它仅支持 MySQL 数据库,并且可以与市面上 Hibernate、MyBatis 等 ORM 框架集成。MySQL Fabric 的文档相对来说比较简略,而且由于是官方提供的解决方案,其社区活跃度也相对较低。
ShardingSphere:
ShardingSphere成员中的sharding-jdbc 以 JAR 包的形式下提供分库分表、读写分离、分布式事务等功能,但仅支持 Java 应用,在应用扩展上存在局限性。
因此,ShardingSphere 推出了独立的中间件 sharding-proxy,它基于 MySQL协议实现了透明的分片和多数据源功能,支持各种语言和框架的应用程序使用,对接的应用程序几乎无需更改代码,分库分表配置可在代理服务中进行管理。
除了支持 MySQL,ShardingSphere还可以支持 PostgreSQL、SQLServer、Oracle等多种主流数据库,并且可以很好地与 Hibernate、MyBatis、JPA等 ORM 框架集成。重要的是,ShardingSphere的开源社区非常活跃。
通过对上述的 5 个分库分表工具进行比较,我们不难发现,就整体性能、功能丰富度以及社区支持等方面来看,ShardingSphere 在众多产品中优势还是比较突出的
三、ShardingSphere成员
ShardingSphere 的主要组成成员为sharding-jdbc、sharding-proxy,它们是实现分库分表的两种不同模式
sharding-jdbc:
它是一款轻量级Java框架,提供了基于 JDBC 的分库分表功能,为客户端直连模式。使用sharding-jdbc,开发者可以通过简单的配置实现数据的分片,同时无需修改原有的SQL语句。支持多种分片策略和算法,并且可以与各种主流的ORM框架无缝集成。
sharding-proxy:
它是基于 MySQL 协议的代理服务,提供了透明的分库分表功能。使用 sharding-proxy 开发者可以将分片逻辑从应用程序中解耦出来,无需修改应用代码就能实现分片功能,还支持多数据源和读写分离等高级特性,并且可以作为独立的服务运行。
四、快速实现
ShardingSphere官网地址:https://shardingsphere.apache.org/
我们先使用sharding-jdbc来快速实现分库分表。相比于 sharding-proxy,sharding-jdbc 适用于简单的应用场景,不需要额外的环境搭建等。可以基于 SpringBoot 的两种方式来实现分库分表,一种是通过YML配置方式,另一种则是通过纯Java编码方式(不可并存)。我们这里就以YML的方式进行简单配置
准备工作
在开始实现之前,需要先对数据库和表的拆分规则进行明确,确定好规则.我们这里按照tenant_id对account表进行拆分.拆分到三个数据库中db0,db1,db2,每个库中又拆分为两张表account_0,account_1
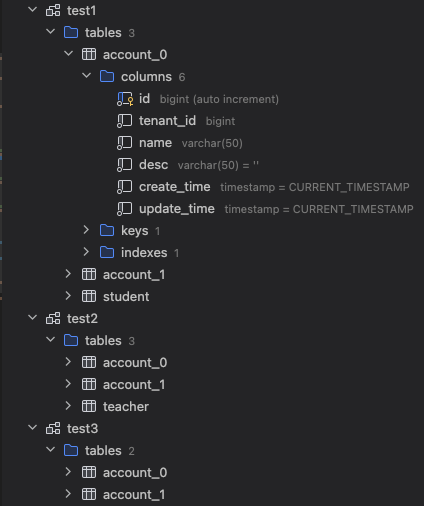
建表语句
CREATE TABLE account(
id BIGINT (15) NOT NULL AUTO_INCREMENT COMMENT 'id',
tenant_id BIGINT (15) NOT NULL COMMENT 'tenantId',
`name` VARCHAR (50) NOT NULL COMMENT 'name',
`desc` VARCHAR (50) NOT NULL DEFAULT '' COMMENT 'desc',
create_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'createTime',
update_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'updateTime',
PRIMARY KEY (id)
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT 'account';依赖引入
公司项目还是用的SpringBoot 2,我这里就用SpringBoot 2.2.6.RELEASE 进行简单的演示
<!-- shardingsphere -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.2.1</version>
</dependency>
<!-- yaml shardingsphere-jdbc-core-spring-boot-starter 5.2.1之前版本不需要-->
<dependency>
<groupId>org.yaml</groupId>
<artifactId>snakeyaml</artifactId>
<version>1.33</version>
</dependency>配置分表信息
可以通过在配置文件中直接配置,也可以通过Java编码去实现.我们这里分片规则比较简单,而且我个人比较喜欢通过配置文件的方式实现
以下是dynamic-datasource和shardingsphere的总配置文件以及部分
### 设置全局连接池配置
spring.datasource.type=com.zaxxer.hikari.HikariDataSource
# 最小空闲数量
spring.datasource.dynamic.hikari.min-idle=10
# 连接池最大数量
spring.datasource.dynamic.hikari.max-pool-size=100
# 连接超时时间
spring.datasource.dynamic.hikari.connection-timeout=60
### 设置全局连接池配置
#spring.datasource.dynamic.druid.initial-size=5
#spring.datasource.dynamic.druid.min-idle=10
#spring.datasource.dynamic.druid.max-active=20
#spring.datasource.dynamic.druid.max-wait=60000
#spring.datasource.dynamic.druid.time-between-eviction-runs-millis=60000
#spring.datasource.dynamic.druid.min-evictable-idle-time-millis=300000
#spring.datasource.dynamic.druid.max-evictable-idle-time-millis=900000
#spring.datasource.dynamic.druid.validation-query=SELECT 1 FROM DUAL
### set default datasource
#设置默认的数据源或者数据源组,默认值即为master
spring.datasource.dynamic.primary=master
#严格匹配数据源,默认false. true未匹配到指定数据源时抛异常,false使用默认数据源
spring.datasource.dynamic.strict=false
#是否优雅关闭数据源,等待一段时间后再将数据源销毁
spring.datasource.dynamic.grace-destroy=true
#主配置
spring.datasource.dynamic.datasource.master.url=jdbc:p6spy:mysql://localhost:3306/test1?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.datasource.dynamic.datasource.master.username=root
spring.datasource.dynamic.datasource.master.password=root
spring.datasource.dynamic.datasource.master.driver-class-name=com.p6spy.engine.spy.P6SpyDriver
#从库配置
spring.datasource.dynamic.datasource.slave_1.url=jdbc:p6spy:mysql://localhost:3306/test2?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.datasource.dynamic.datasource.slave_1.username=root
spring.datasource.dynamic.datasource.slave_1.password=root
spring.datasource.dynamic.datasource.slave_1.driver-class-name=com.p6spy.engine.spy.P6SpyDriver
# 这里可以单独对slave_1数据源的连接池进行配置
spring.datasource.dynamic.datasource.slave_1.hikari.min-idle=5
spring.datasource.dynamic.datasource.slave_2.url=jdbc:p6spy:mysql://localhost:3306/test3?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.datasource.dynamic.datasource.slave_2.username=root
spring.datasource.dynamic.datasource.slave_2.password=root
spring.datasource.dynamic.datasource.slave_2.driver-class-name=com.p6spy.engine.spy.P6SpyDriver
### 配置shardingsphere-jdbc
# 数据源名称,多数据源以逗号分隔
spring.shardingsphere.datasource.names=db0,db1,db2
# 数据源db0配置
spring.shardingsphere.datasource.db0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db0.driver-class-name=com.mysql.cj.jdbc.Driver
#spring.shardingsphere.datasource.db0.jdbc-url=jdbc:mysql://localhost:3306/test1?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.db0.jdbc-url=jdbc:p6spy:mysql://localhost:3306/test1?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.db0.username=root
spring.shardingsphere.datasource.db0.password=root
spring.shardingsphere.datasource.db1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db1.driver-class-name=com.mysql.cj.jdbc.Driver
#spring.shardingsphere.datasource.db1.jdbc-url=jdbc:mysql://localhost:3306/test2?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.db1.jdbc-url=jdbc:p6spy:mysql://localhost:3306/test2?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.db1.username=root
spring.shardingsphere.datasource.db1.password=root
spring.shardingsphere.datasource.db2.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db2.driver-class-name=com.mysql.cj.jdbc.Driver
#spring.shardingsphere.datasource.db2.jdbc-url=jdbc:mysql://localhost:3306/test3?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.db2.jdbc-url=jdbc:p6spy:mysql://localhost:3306/test3?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.db2.username=root
spring.shardingsphere.datasource.db2.password=root
### 分片规则配置
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.type=INLINE
# 分片算法表达式
spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.props.algorithm-expression=db${tenant_id % 3}
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.type=INLINE
# 分片算法表达式
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.props.algorithm-expression=account_${tenant_id % 2}
# 对account逻辑表与物理表进行映射
spring.shardingsphere.rules.sharding.tables.account.actual-data-nodes=db$->{0..2}.account_$->{0..1}
# 分库策略 分片列名称
spring.shardingsphere.rules.sharding.tables.account.database-strategy.standard.sharding-column=tenant_id
# 分库策略 分片算法名称
spring.shardingsphere.rules.sharding.tables.account.database-strategy.standard.sharding-algorithm-name=database-inline
# 分表策略 分片列名称
spring.shardingsphere.rules.sharding.tables.account.table-strategy.standard.sharding-column=tenant_id
# 分表策略 分片算法名称
spring.shardingsphere.rules.sharding.tables.account.table-strategy.standard.sharding-algorithm-name=table-inline
# 展示修改后的sql
spring.shardingsphere.props.sql.show=true
# https://github.com/gavlyukovskiy/spring-boot-data-source-decorator
decorator.datasource.p6spy.enable-logging=true
decorator.datasource.p6spy.log-format=\ntime:%(executionTime) || sql:%(sql)\n
decorator.datasource.p6spy.logging=slf4j
decorator.datasource.p6spy.multiline=true
decorator.datasource.p6spy.log-file=spy.log分片算法类型以及分片算法详情可以在官网自行查看,这里没有配置主键id的生成规则,所以每张表里的主键id是根据每张表的值自增.
五、将shardingsphere数据源添加到动态数据源中
经过上面的步骤已经配置好shardingsphere数据源了,但是我们在项目中使用了dynamic-datasource动态数据源去管理多数据源,所以我们还需要将shardingsphere数据源托管给dynamic-datasource
package com.example.dynamicdatasource.config;
import com.baomidou.dynamic.datasource.DynamicRoutingDataSource;
import com.baomidou.dynamic.datasource.creator.DataSourceProperty;
import com.baomidou.dynamic.datasource.creator.DefaultDataSourceCreator;
import com.baomidou.dynamic.datasource.provider.AbstractDataSourceProvider;
import com.baomidou.dynamic.datasource.provider.DynamicDataSourceProvider;
import com.baomidou.dynamic.datasource.spring.boot.autoconfigure.DynamicDataSourceAutoConfiguration;
import com.baomidou.dynamic.datasource.spring.boot.autoconfigure.DynamicDataSourceProperties;
import com.google.common.collect.Lists;
import org.springframework.boot.SpringBootConfiguration;
import org.springframework.boot.autoconfigure.AutoConfigureBefore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Lazy;
import org.springframework.context.annotation.Primary;
import javax.annotation.Resource;
import javax.sql.DataSource;
import java.util.Map;
@Configuration
@AutoConfigureBefore({DynamicDataSourceAutoConfiguration.class, SpringBootConfiguration.class})
public class DataSourceConfiguration {
/**
* 分表数据源名称
*/
public static final String SHARDING_DATA_SOURCE_NAME = "sharding";
/**
* 动态数据源配置项
*/
@Resource
private DynamicDataSourceProperties dynamicDataSourceProperties;
@Resource
private DefaultDataSourceCreator defaultDataSourceCreator;
/**
* shardingjdbc有四种数据源,需要根据业务注入不同的数据源
*
* <p>1. 未使用分片, 脱敏的名称(默认): shardingDataSource;
* <p>2. 主从数据源: masterSlaveDataSource;
* <p>3. 脱敏数据源:encryptDataSource;
* <p>4. 影子数据源:shadowDataSource
*
* shardingjdbc默认就是shardingDataSource
* 如果需要设置其他的可以使用
* @Resource(value="") 设置
*/
@Lazy
@Resource
private DataSource shardingDataSource;
@Bean
public DynamicDataSourceProvider dynamicDataSourceProvider() {
Map<String, DataSourceProperty> datasourceMap = dynamicDataSourceProperties.getDatasource();
return new AbstractDataSourceProvider(defaultDataSourceCreator) {
@Override
public Map<String, DataSource> loadDataSources() {
Map<String, DataSource> dataSourceMap = createDataSourceMap(datasourceMap);
dataSourceMap.put(SHARDING_DATA_SOURCE_NAME, shardingDataSource);
return dataSourceMap;
}
};
}
@Primary
@Bean
public DataSource dataSource(DynamicDataSourceProvider dynamicDataSourceProvider) {
DynamicRoutingDataSource dataSource = new DynamicRoutingDataSource(Lists.newArrayList(dynamicDataSourceProvider));
dataSource.setPrimary(dynamicDataSourceProperties.getPrimary());
dataSource.setStrict(dynamicDataSourceProperties.getStrict());
dataSource.setStrategy(dynamicDataSourceProperties.getStrategy());
dataSource.setP6spy(dynamicDataSourceProperties.getP6spy());
dataSource.setSeata(dynamicDataSourceProperties.getSeata());
return dataSource;
}
}六、测试结果
public interface AccountService {
void saveBatch(List<AccountPO> list);
List<AccountPO> list();
List<AccountPO> listByTenantId(Long tenantId);
}@Service
public class AccountServiceImpl implements AccountService {
@Resource
private AccountMapper accountMapper;
@Override
public void saveBatch(List<AccountPO> list) {
accountMapper.saveBatch(list);
}
@Override
public List<AccountPO> list() {
return accountMapper.list();
}
@Override
public List<AccountPO> listByTenantId(Long tenantId) {
return accountMapper.listByTenantId(tenantId);
}
}@DS("sharding")
public interface AccountMapper {
@Insert("<script>insert into account (tenant_id, name) values " +
"<foreach collection='list' item='item' index='index' separator=','>" +
"(#{item.tenantId}, #{item.name})" +
"</foreach></script>")
void saveBatch(@Param("list") List<AccountPO> list);
@Select("select * from account")
List<AccountPO> list();
@Select("select * from account where tenant_id = #{tenantId}")
List<AccountPO> listByTenantId(Long tenantId);
}@Test
void testCreateAccount() {
List<AccountPO> list = new ArrayList<>();
for (int i = 1; i <= 12; i++) {
AccountPO accountPO = new AccountPO();
accountPO.setName("hahaha" + i).setTenantId((long) i);
list.add(accountPO);
}
accountService.saveBatch(list);
}运行后可以看到结果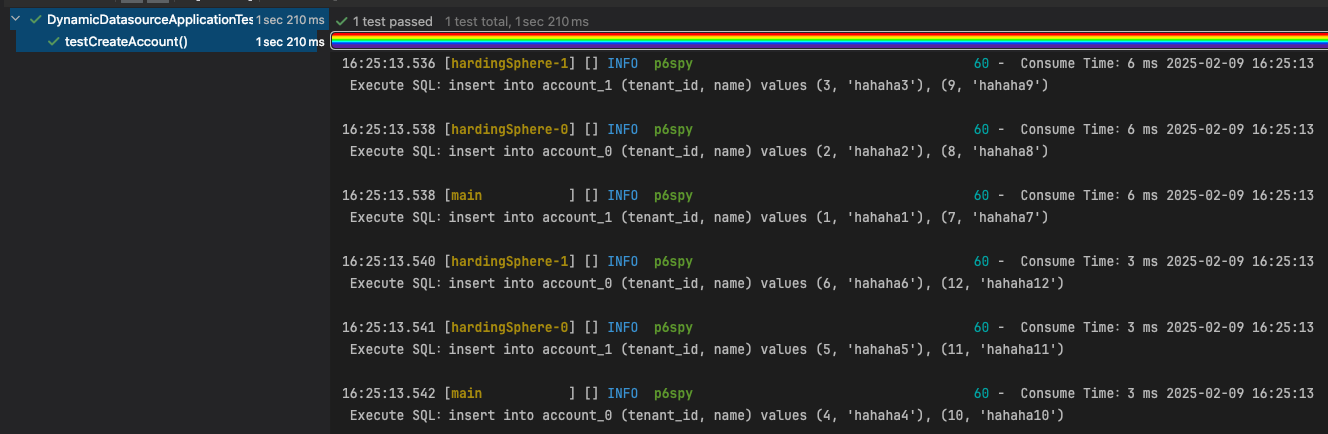
@Test
void testQueryAccount() {
List<AccountPO> list = accountService.listByTenantId(6L);
list.forEach(System.out::println);
list = accountService.list();
list.forEach(System.out::println);
}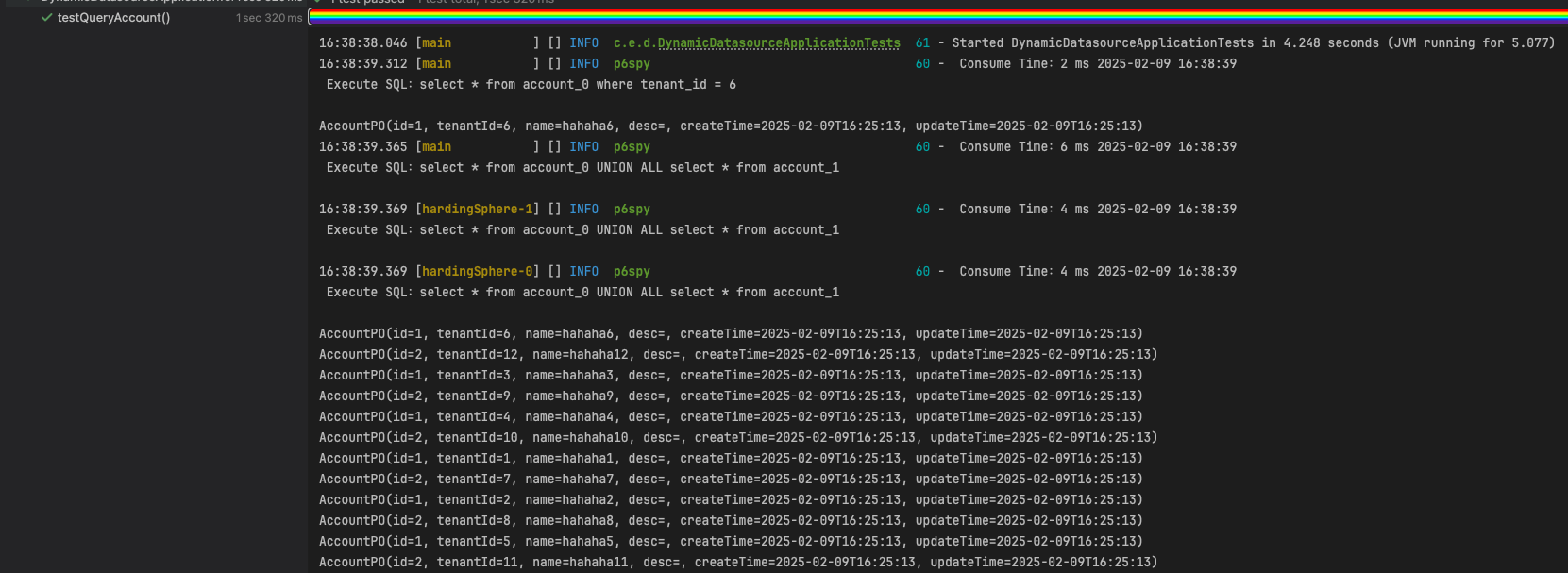
上面配置的数据库分片规则是db${tenant_id % 3},表分片规则是account_${tenant_id % 2} 结果是符合预期的
多数源集成p6spy详情请看上篇文章《springboot+mybatis-plus多数据源实现以及结合 p6spy 打印 SQL 日志》
